
Interpretable Hybrid AI with Uncertainty Measure
Funding: UJM New Lecture Fondation - 5k€
Period: From January 2025 to December 2025
Contexte
Traditional AI systems, particularly deep learning models, have shown remarkable success in various domains, including healthcare, finance, and manufacturing. However, these models often operate as “black boxes”, making it difficult to understand their decision-making processes. This opacity has led to concerns about their trustworthiness, reliability, fairness, and accountability, especially in high-stakes applications.
To address these concerns, the field of Explainable AI (XAI) emerged, focusing on improving the interpretability and transparency of machine learning models by providing post hoc explanations for black-box models or constructing new self-interpretable models. Popular explanations include future importance estimation (LIME, SHAP, Saliency map, etc.), instance-based explanations (prototypes and counterfactual examples), surrogate models, and attention mechanisms. However, many of these methods offer post hoc explanations, which may not fully align with the real reasoning process of the model. In addition, a key limitation of most conventional XAI techniques is their inability to allow direct intervention in a model’s decision-making process. While they explain why a model made a decision, they do not provide mechanisms to control or adjust the model’s reasoning in response to errors or bias.
For these issues, Concept Bottleneck Models (CBMs) have recently gained attention as a promising approach to making AI systems inherently interpretable by predicting through predefined human-understandable concepts, which makes the basis of prediction clear and enables interventions by correcting predicted concepts before the final decision is made. This kind of model combines the black-box model and the interpretable model, which is called hybrid AI techniques. Unlike traditional raw-picture-to-prediction models, CBMs consist of two main stages:
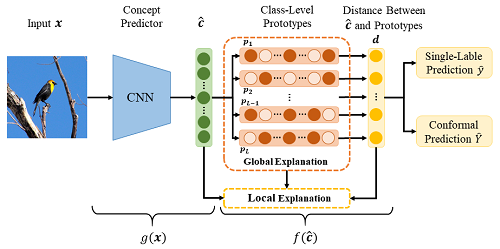
- Concept prediction: The first stage predicts human-understandable intermediate concepts (bottleneck) from input data. For example, in bird classification, concepts might include “pointed beak”, “black forehead”, “gray tail”, etc.
- Task prediction: In the second stage, the model uses the predicted concepts to make the final task prediction, such as species of birds.
Objectives
For a given image, the first step of CBMs usually predicts the existence (binary values or probabilities) of predefined concepts. In this case, the second step is equivalent to a classification task based on tabular data. In order to guarantee the interpretability of the whole model, only a simple model is usually implemented for the second step, e.g., a single-layer fully connected network (equivalent to softmax regression). However, because of the fragile expressivity of the single-layer network, the final classification performance decreases. On the contrary, if a complex model is used for the second step, we may know which concepts are used to make the prediction, but we cannot understand how these concepts derive the prediction. The model falls into the “black-box” case for tabular data. For this consideration, in this work, we will try to propose a new inherently interpretable classifier to make predictions based on the concepts detected by the first stage of the model.
The main idea of this inherently interpretable classifier is to learn prototypes for each class. Each feature of these prototypes is binary, representing the existence or non-existence of the corresponding predefined human-understandable concept. Then, the final prediction is based on the distance between the detected concepts and the learned class prototypes. In this work, we will mainly focus on the following points associated with this kind of classifier.
- Construct a special network architecture to learn class prototypes;
- Compare the classification performance with other interpretable classifiers, such as single-layer fully connected networks, decision trees, and logical rules;
- Determine efficient and effective interventions (or counterfactual examples) to correct predictions if they are wrong;
- Discuss the unification of interpretations based on prototypes, counterfactual examples, and rules according to the proposed classifier;
- Measure uncertainty from detected concepts to final predictions based on distance;
- Explore its capacity for outlier (few or too many concepts exist) detection and imprecise prediction making.